Preparing documents and keywords
Please read Preparation for the reading of documents and creating a list of keywords. We use the US Presidential inaugural address data we prapared (documents and keywords).
Fitting the model
We pass the output of the keyATM_read function and
keywords to the keyATM function.
Additionally, we need to specify the number of topics without
keywords (the no_keyword_topics argument) and model. Since
this example does not use covariates or time stamps, base
is the appropriate model.
To guarantee the replicability, we recommend to set the random seed
in the option argument (see here
for other options). The default number of iterations is 1,500.
out <- keyATM(
docs = keyATM_docs, # text input
no_keyword_topics = 5, # number of topics without keywords
keywords = keywords, # keywords
model = "base", # select the model
options = list(seed = 250)
)The default number of iterations is 1500. Please check
this page for available options.
You can resume the iteration by specifying
the resume argument.
Saving the model
Once you fit the model, you can save the model with the
saveRDS() function for replication. We strongly recommend
to save the fitted model.
saveRDS(out, file = "SAVENAME.rds")To load the model, you can use readRDS() function.
out <- readRDS(file = "SAVENAME.rds")Interpreting results
There are two main quantities of interest in topic models. First, topic-word distribution represents the relative frequency of words for each topics, characterizing the topic content. Second, document-topic distribution represents the proportions of topics for each document, reflecting the main themes of the document and often called topic prevalence.
Since typical corpus contains several thousands of unique terms, we usually scrutinize ten to fifteen words that have high probabilities in a given topic, which is called top words of a topic.
The top_words() function returns a table of top words
for each of estimated topics. Keywords assigned to a keyword topic are
suffixed with a check mark. Keywords from another keyword topic are
labeled with the topic id of that category.
In the table below, “law”, “laws”, and “executive” are keywords of the Government topic, while “peace” appears in top words of the Other_3 topic, it is a keyword of the peace topic.
top_words(out)## 1_Government 2_Congress 3_Peace 4_Constitution 5_ForeignAffairs
## 1 great country world [✓] states government
## 2 one national new constitution [✓] union
## 3 american congress [✓] america great war [✓]
## 4 government made nation power united
## 5 make policy let rights [✓] public
## 6 laws [✓] best peace [✓] nations interests
## 7 law [✓] duty freedom [✓] administration state
## 8 hope party [✓] work whole foreign [✓]
## 9 citizens office know institutions powers
## 10 executive [✓] order life necessary principles
## Other_1 Other_2 Other_3 Other_4 Other_5
## 1 government justice people spirit free
## 2 peace [3] much now nation first
## 3 support men every well long
## 4 public system time citizens man
## 5 political part years one power
## 6 good many just high yet
## 7 federal force among trust others
## 8 prosperity action future character means
## 9 secure important ever since even
## 10 proper resources equal honor changeResearchers can also examine how likely each topic appears in the
corpus with plot_topicprop(). This function creates a
figure that shows the expected proportions of the corpus belonging to
each estimated topic along with the top three words associated with the
topic. The figure below demonstrates that the ``Peace’’ topic is most
likely to appear in the corpus.
plot_topicprop(out, show_topic = 1:5)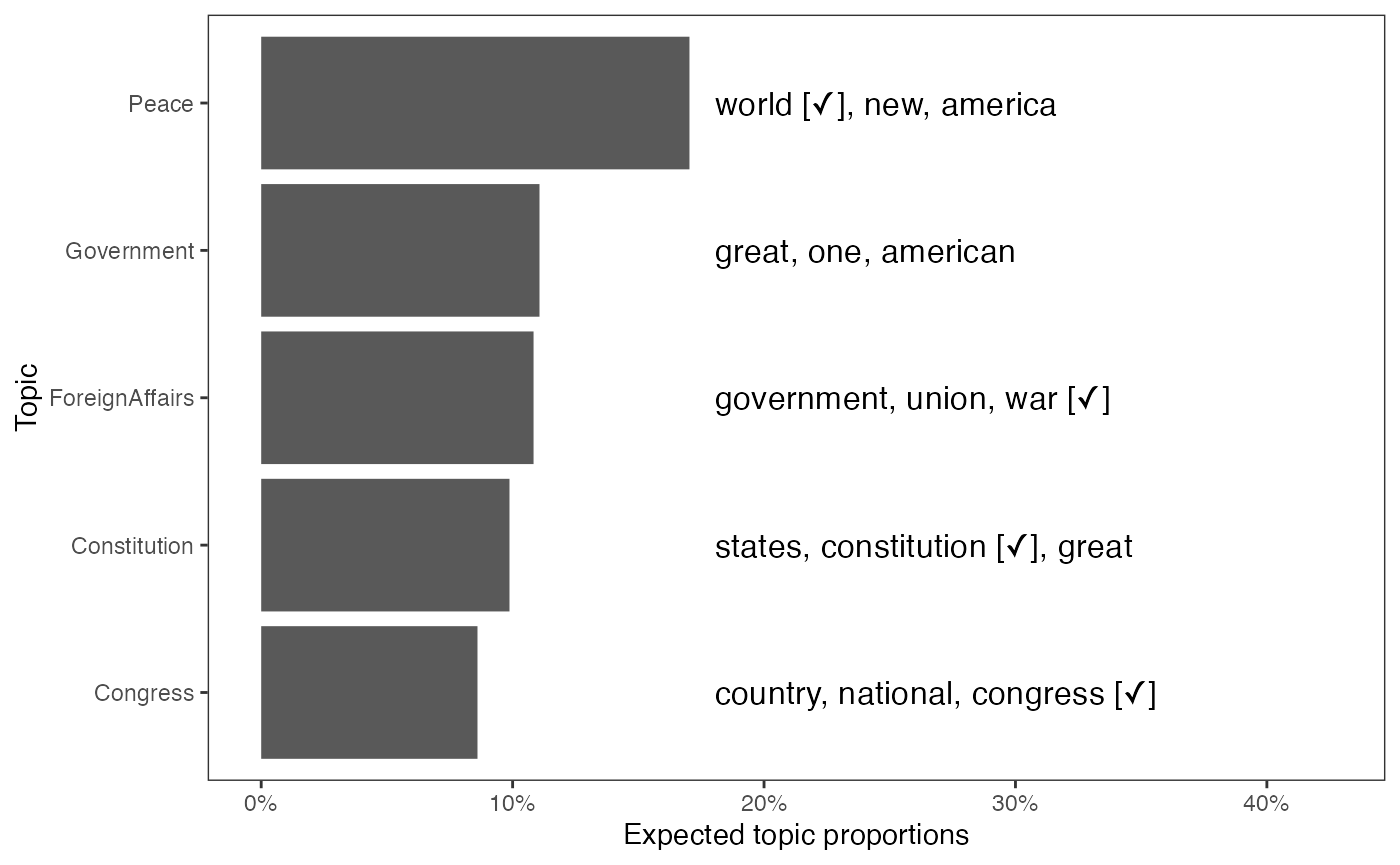
To explore documents that are highly associated with each topic, the
top_docs() function returns a table of document indexes in
which a topic has high proportion.
The table below indicates, for example, that the ninth document in the corpus has the highest proportion of the Government topic among all other documents.
top_docs(out)## 1_Government 2_Congress 3_Peace 4_Constitution 5_ForeignAffairs Other_1
## 1 58 28 46 19 16 31
## 2 53 21 53 18 10 36
## 3 32 22 47 23 11 27
## 4 55 29 52 15 12 26
## 5 54 37 50 9 15 25
## 6 51 34 54 14 8 2
## 7 52 31 51 24 7 28
## 8 57 23 55 12 1 23
## 9 45 25 44 17 13 24
## 10 50 26 57 6 5 35
## Other_2 Other_3 Other_4 Other_5
## 1 41 47 14 44
## 2 30 20 6 43
## 3 35 21 3 45
## 4 32 57 1 48
## 5 37 2 17 56
## 6 36 45 39 42
## 7 33 48 4 51
## 8 31 50 32 52
## 9 29 46 2 49
## 10 8 53 7 40Researchers may want to obtain the entire document-topic distribution
and topic-word distribution. The output of the keyATM()
function contains both quantities.
out$theta # Document-topic distribution
out$phi # Topic-word distributionThe keyATM provides other functions to diagnose and explore the fitted model. First, it is important to check the model fitting. If the model is working as expected, we would observe an increase trend for the log-likelihood and an decrease trend for the perplexity.
Also the fluctuation of these values get smaller as iteration
increases. The plot_modelfit() function visualizes the
within sample log-likelihood and perplexity and the created figure can
be saved with the save_fig() function.
fig_modelfit <- plot_modelfit(out)
fig_modelfit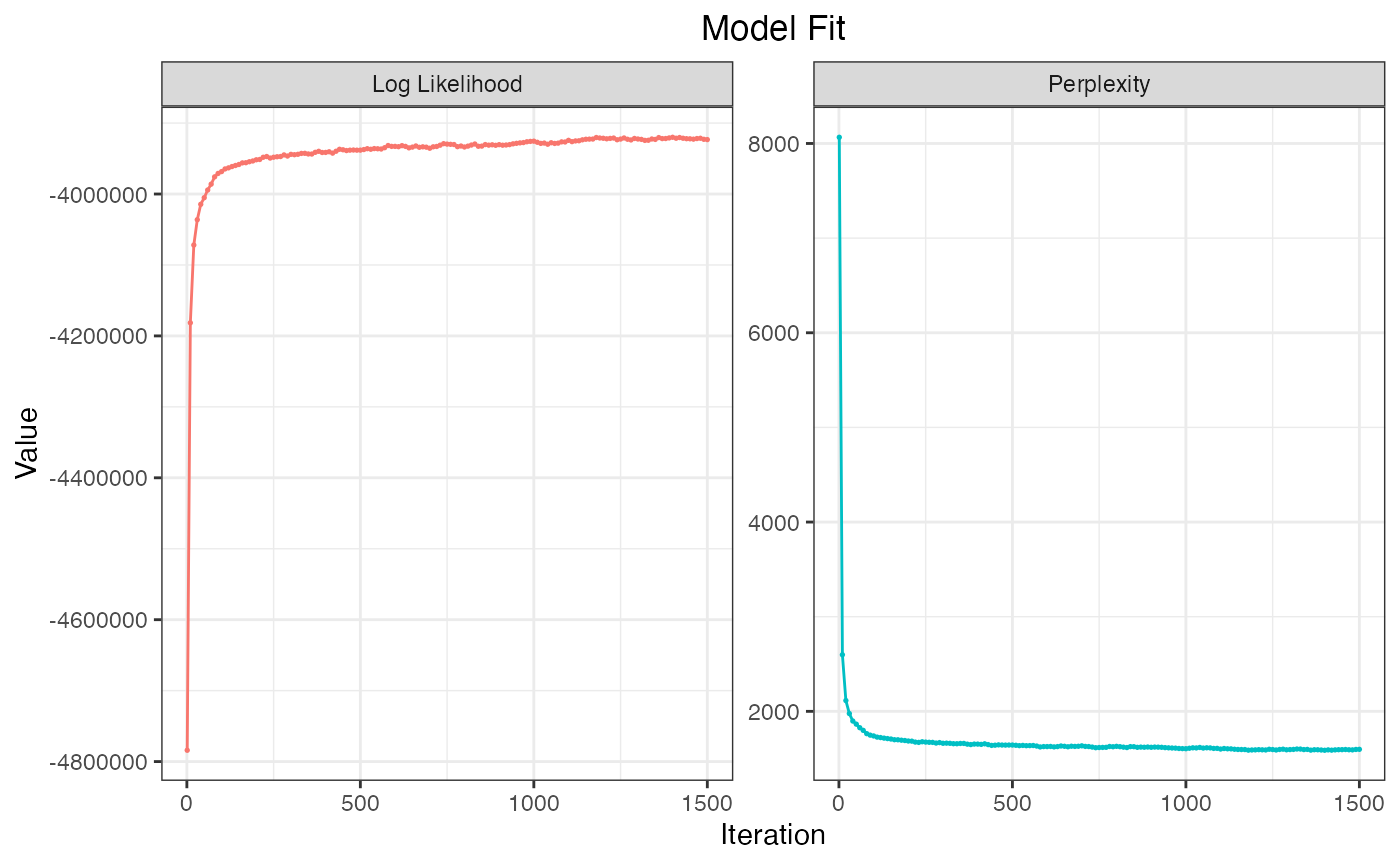
save_fig(fig_modelfit, "figures/base_modelfit.pdf", width = 7, height = 5)Furthermore, the keyATM can visualize , the prior for the document-topic distribution, and , the probability that each topic uses keyword topic-word distribution. Values of these parameters should also stabilize over time.
plot_alpha(out)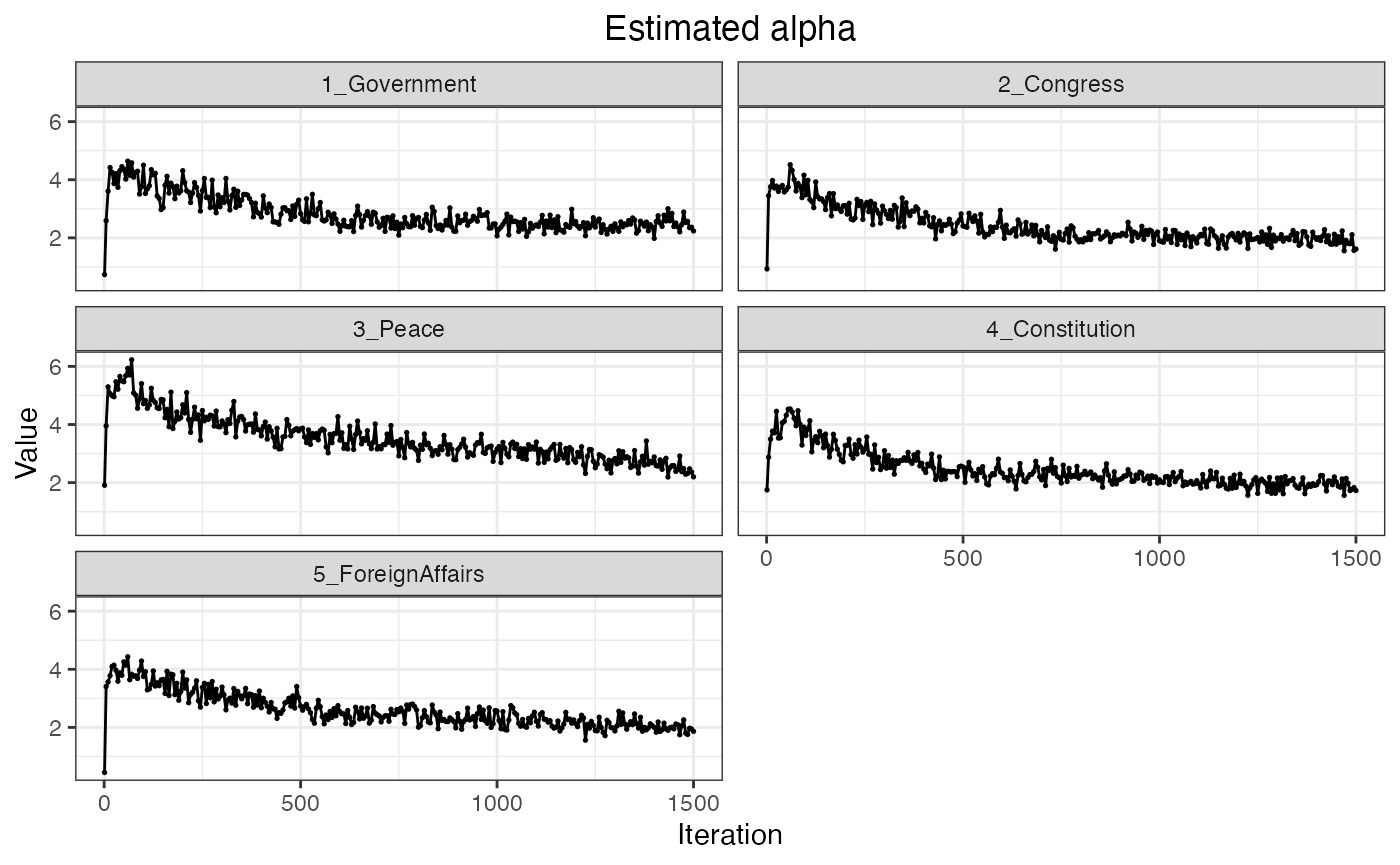
plot_pi(out)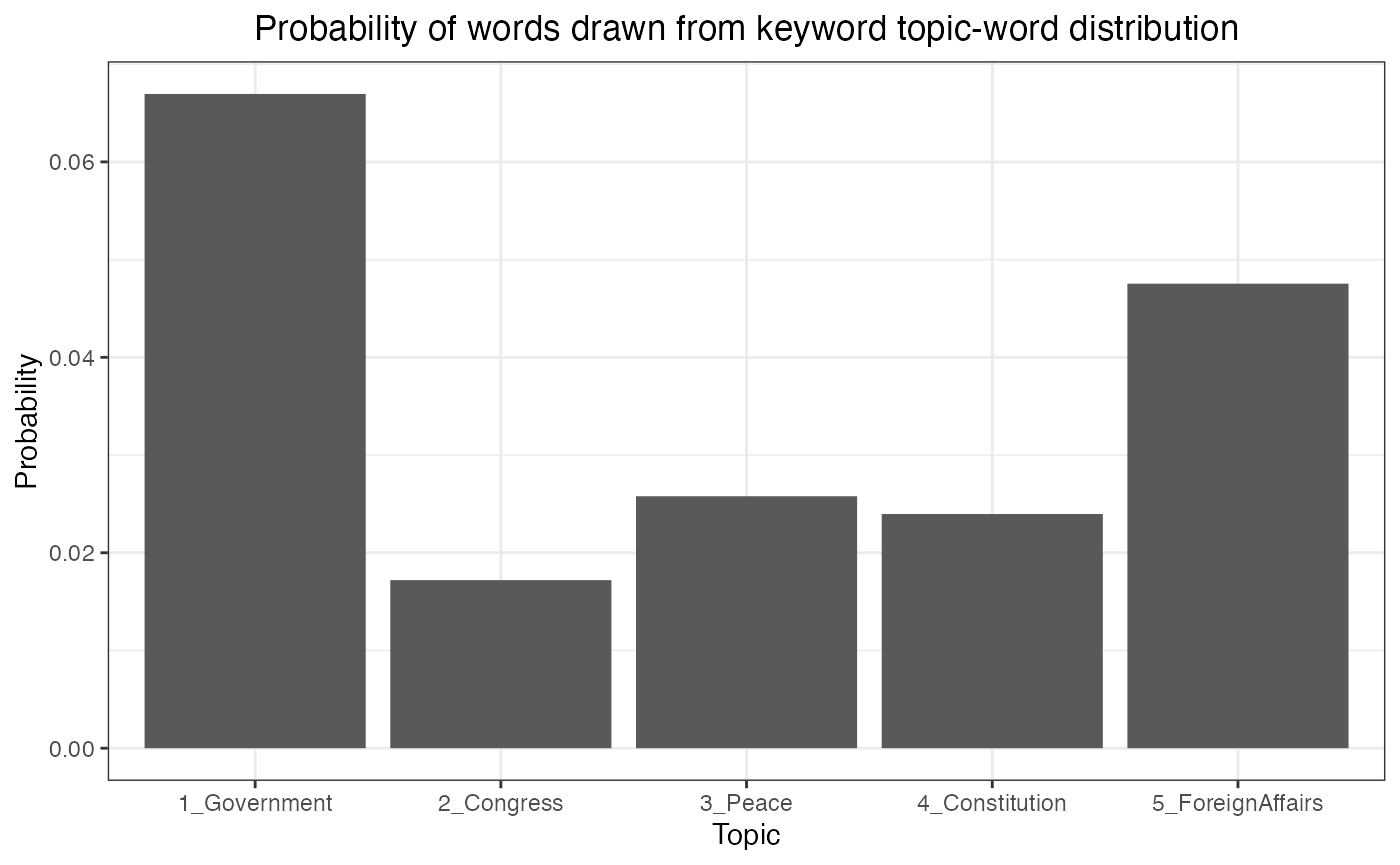
We can use the save_fig() function for both the
plot_alpha() and the plot_pi() functions.